-
NExT-GPT: Any-to-Any Multimodal LLM 정리논문 정리 2025. 7. 9. 16:39
- 연구 목적 및 문제 정의
- 모델 구조 (전체 아키텍처)
- 학습 전략
- 실험 결과 요약
- 결론 및 핵심 기여
- 이 연구의 의의와 우리에게 주는 시사점
1. 연구 목적 및 문제 정의
연구 목표
- NExT-GPT는 어떤 모달리티든 입력하고 어떤 모달리티든 출력할 수 있는
- 범용 멀티모달 대형 언어 모델(MM-LLM)을 제안한다.
- 목표는 텍스트, 이미지, 오디오, 비디오의 조합을 자유롭게 처리할 수 있는
- “Any-to-Any” 멀티모달 시스템 구축이다.
기존 연구의 한계
기존 MM-LLM의 구조
- 대부분의 멀티모달 모델은 LLM 중심 + 어댑터 연결 구조
- 입력(이미지/오디오 등)은 인식 가능하지만, 출력은 거의 항상 텍스트
- 예시: BLIP-2, Flamingo, LLaVA, MiniGPT-4 등
주요 한계점
항목내용
입력 편향 텍스트 외 모달 입력은 가능하나 출력은 텍스트로만 제한 파이프라인 구조 외부 툴을 호출하는 방식 → 정보 전이 시 노이즈/에러 발생 학습 제한 전체 시스템이 end-to-end로 학습되지 않아 추론 능력 약함 유연성 부족 모달 전환이나 조합이 제한적, 실사용 시나리오 반영 어려움 해결하고자 하는 핵심 문제
- 어떤 모달리티든 입력할 수 있고,인간 수준의 유연한 AI 시스템을 만들 수 있을까?
- 지시에 따라 적절한 모달리티로 출력할 수 있는
- 즉, 입력/출력 모두 자유로운 Any-to-Any 멀티모달 이해 및 생성이 가능한
- end-to-end 학습 구조를 설계하는 것이 본 논문의 중심 과제다.
2. 모델 구조 (전체 아키텍처)
전체 구조 개요
NExT-GPT는 다음의 3단계 구조로 구성된 end-to-end any-to-any MM-LLM 시스템이다.

1. Multimodal Input Encoding (왼쪽)
- Text: 별도 인코더 없이 바로 LLM으로 전달된다.
- Image / Audio / Video:
- 각각 Image Encoder / Audio Encoder / Video Encoder를 거쳐 벡터로 인코딩됨
- ⛸️ 파란 눈송이(❄️) = 사전학습된 frozen 상태, 학습되지 않음
- 이후 Input Projection Layer를 통해 각 모달 표현을 LLM이 이해 가능한 언어 형태로 변환
- 🔥 불꽃 아이콘 = 학습되는 부분
2. LLM-centric Alignment & Semantic Understanding (중앙)
- LLM (예: Vicuna)은 멀티모달 표현들을 받아 의미를 해석하고 추론을 수행
- 동시에 다음을 생성:
- 텍스트 응답
- Modality Signal Tokens: 어떤 모달로 출력할지를 알려주는 신호
3. Instruction-following Alignment & Multimodal Output Generation (오른쪽)
- Modality Signal Tokens는 Output Projection Layer를 거쳐 해당 모달 디코더로 전달
- 디코더는 각각 다음과 같은 역할을 수행:
- Image Diffusion → 이미지 생성
- Audio Diffusion → 오디오 생성
- Video Diffusion → 비디오 생성
- 모두 ❄️ frozen 상태, 학습되지 않음
- 최종적으로 사용자가 요구한 모달의 출력이 생성됨
핵심 요약
영역설명
영역 설명 입력 인코딩 기존 인코더 + 학습되는 Projection Layer로 모달 데이터를 LLM 형식으로 변환 중심 처리 LLM이 모든 정보를 통합하여 의미 이해 및 생성 방향 결정 출력 생성 디퓨전 디코더로 멀티모달 출력 생성, Projection만 fine-tuning 됨 학습 구조 전체 모델 중 학습되는 부분은 🔥로 표시된 Projection Layer 뿐 (경량 구조)
📌 왜 중요한가?
이 구조는 단순한 모달 연동이 아니라, LLM 중심의 의미 처리 및 생성 제어를 통해 완전한 Any-to-Any 멀티모달 흐름을 end-to-end로 통합한다. 또한, 대부분의 구성요소는 frozen 상태이므로, 낮은 비용으로 고성능 확장성을 제공한다.
3. 학습 전략
NExT-GPT는 대규모 멀티모달 모델을 효율적으로 학습하기 위해 전체 시스템을 처음부터 학습하지 않고, 다음과 같은 전략들을 활용하여 최소한의 연산 자원으로 고성능을 달성하였다.
🔹 1. 사전 학습된 고성능 인코더 및 디코더 재사용
- CLIP, ImageBind, Stable Diffusion 등 기존의 성능 검증된 인코더와 디코더를 활용함.
- 처음부터 모델을 학습하지 않고, 기존 자원을 활용함으로써 시간과 비용 절감.
- 다양한 modality 확장 가능성을 확보.
🔹 2. Off-the-shelf 파라미터 활용 및 cold-start 문제 회피
- 기존 모델의 학습된 파라미터를 불러와 재활용함으로써 cold-start(초기 가중치로부터 학습 시작)의 비효율성 제거.
- 이는 학습 안정성과 확장성을 동시에 확보하는 전략임.
🔹 3. 최소 파라미터만 미세 조정 (Fine-tuning)
- 전체 모델 중 Input/Output Projection Layer만 미세조정하며, 나머지 인코더·디코더·LLM은 모두 고정(frozen).
- 전체 파라미터 중 약 1%만 학습에 사용되어 학습 자원을 최소화.
- 미세조정된 projection layer가 modality 간 feature alignment를 담당함.
🔹 4. 양방향 정렬 학습
인코딩 정렬: LLM-centric Alignment

- ImageBind와 같은 인코더의 patch-level feature를 개념 단위 concept token으로 그룹핑하여 LLM이 이해 가능한 언어 표현으로 변환함.
- 이를 통해 텍스트 기반 LLM과 시각/음성/영상 특징 간 의미 정렬을 수행.
전체 흐름 요약
입력 (Image, Audio, Video) → Encoder → Patch Representation → Concept Token 변환 → LLM → Caption 생성 → 정답과 Cross-Entropy 비교로 학습
각 구성 요소 설명
1. Image / Audio / Video
- 입력 모달리티 3종: 이미지, 오디오, 비디오
2. Encoder (이미지/오디오/비디오 인코더)

- 사전학습된 인코더 (예: CLIP, ImageBind, HuBERT 등)
- ❄️ 표시 = 파라미터가 고정됨 (Frozen)
3. Patch Representation

- 인코더 출력은 각 입력을 patch 단위 grid feature로 분할한 표현이다.
- 예: 이미지 → 16×16 패치 → 각 패치의 벡터 표현
4. Input Projection 모듈
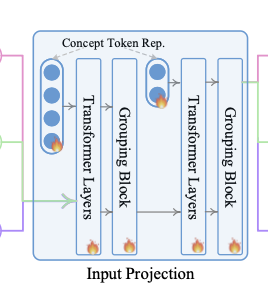
- 여러 개의 Transformer Layer와 Grouping Block으로 구성됨 🔥
- 이 모듈은 patch feature를 다음과 같이 처리:
- Transformer Layer: 각 patch 간 관계를 학습
- Grouping Block: patch들을 개념 단위(semantic token)로 집계
- Concept Token Representation: 최종적으로 LLM이 이해할 수 있는 개념 단위 표현
5. Concept Image/Audio/Video Representation

- 세 모달리티별로 LLM에 들어가는 개념 표현 벡터
6. LLM (예: Vicuna-7B)

- ❄️ Frozen 상태
- 입력된 개념 표현을 바탕으로 Image / Audio / Video Caption을 생성
7. Caption 생성 → Cross Entropy Loss
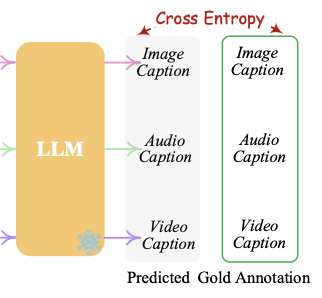
- 생성된 캡션과 Ground Truth(정답 캡션)을 비교하여 학습
- 비교는 Cross-Entropy Loss로 계산되어 Input Projection 레이어들을 업데이트
🎯 학습 목적
- 입력 모달리티(이미지, 오디오, 비디오)를 언어 표현(Linguistic Space)으로 효과적으로 정렬(alignment)하여,
- LLM이 모든 모달을 텍스트처럼 이해하고 응답할 수 있도록 만드는 것
요점 정리
항목 설명 입력 이미지, 오디오, 비디오 중간 표현 Patch-level feature → Concept Token Representation 핵심 학습 대상 Input Projection 내부의 🔥 레이어들 (Transformer + Grouping) 출력 LLM이 생성한 Caption (텍스트 설명) 손실 함수 Cross-Entropy Loss (예측된 캡션 vs. 정답) 고정된 모듈 Encoder, LLM (Vicuna) ❄️
이 구조는 LLM이 각 모달의 의미를 개념 수준에서 이해하고 텍스트로 표현할 수 있도록 정렬하는 핵심 단계이다. 즉, "LLM에게 이미지/비디오/오디오를 언어처럼 느끼게 만든다"고 요약할 수 있다.
디코딩 정렬: Instruction-following Alignment

- LLM이 생성한 modality-specific signal token을 디코더가 이해 가능한 조건 입력으로 정렬.
- 학습 시 signal token과 diffusion model의 조건 텍스트 표현 간 representation distance 최소화.
전체 구조 흐름 요약
LLM → Signal Tokens (Image, Audio, Video)
→ Output Projection (Transformer + Linear)
→ Diffusion 모델 조건 입력
→ Content 생성 + Loss 계산 (Alignment + Denoising)
구성 요소별 설명
1. LLM Output Representation

- LLM은 텍스트 응답 외에도 모달 지시 토큰을 생성한다:
- Image Signal Token
- Audio Signal Token
- Video Signal Token
- ❄️ = LLM은 동결(frozen) 상태
2. Image Output Projection (학습 대상 🔥)

- LLM의 signal token을 디퓨전 모델이 해석할 수 있는 표현으로 변환하는 projection 모듈
- 구조: Transformer Encoder + Decoder + Linear Layer
- 학습 대상 = signal token ↔ 디퓨전 조건 간 의미적 정렬 수행
3. Image Diffusion

- 이미지 생성을 위한 Stable Diffusion 백본 사용
- Text Encoder + U-Net로 구성되어 있음 (❄️ Frozen)
- 조건으로 주어지는 정보:
- LLM signal token 표현 (projected)
- 텍스트 설명
4. Loss 구성 (손실 함수)
- Caption-alignment Loss
- LLM이 생성한 signal token의 표현과,
- Diffusion 모델 내 Text Encoder가 생성한 조건 표현 사이의 표현 거리 최소화
- Conditional Latent Denoising Loss
- 생성된 이미지가 실제 타겟 이미지와 유사하도록
- U-Net의 latent output에 대해 디노이징 손실 적용
🎯 핵심 요약
항목 설명 목적 LLM의 모달 지시(signal token)가 생성 모델에 정확히 반영되도록 정렬 학습 주요 구성 Output Projection (Transformer 기반), Signal Token, Diffusion 학습 범위 Output Projection Layer만 학습 🔥 손실 구성 (1) 표현 정렬 (caption-alignment), (2) 생성 품질 향상 (denoising loss) 생성기 디퓨전 기반 생성기 (이미지: Stable Diffusion, 비디오: Zeroscope, 오디오: AudioLDM)
📌 왜 중요한가?
- 기존 MM-LLM 시스템은 텍스트 지시만으로 디코더를 제어했다면, NExT-GPT는 모달별 신호 토큰을 생성하고, 그것을 디퓨전 생성기로 직접 연동시킴으로써 정밀하고 유연한 다중 모달 생성을 가능하게 한다.
이 구조 덕분에 NExT-GPT는 단순히 텍스트 응답을 넘어서, 이미지, 비디오, 오디오 생성까지 일관되고 통합적으로 수행 가능한 진정한 Any-to-Any 모델로 작동한다.
🔹 5. MosIT 데이터셋 구축
- 기존 instruction tuning 데이터는 text 중심이라 한계가 있어, 새로운 modality-switching 데이터셋 MosIT 직접 구축.
- 총 5,000개의 고품질 대화 예시를 포함하며, 다중 모달 간의 전환, 3~7턴의 복잡한 대화, 명시적·암시적 요청, 추론/계획/감정 응답 등 인간 수준 대화 흐름을 반영.
🔹 6. LoRA 기법을 활용한 경량화 학습
- LoRA(Low-Rank Adaptation)를 사용하여 LLM의 일부 파라미터만 효율적으로 업데이트함.
- 이 방식은 연산 자원 소모를 줄이면서도 모델의 표현력은 유지시킬 수 있음.
- LoRA는 projection layer 외에 일부 LLM 내부 모듈에도 적용됨.

이 그림은 Figure 3: modality-switching instruction tuning의 전체 과정을 시각화한 것이다.
NExT-GPT가 텍스트 기반 지시를 이해하고, 그에 따라 적절한 멀티모달 출력을 생성하도록 학습되는 과정을 보여준다.
전체 흐름 요약
1. Input Instructions (왼쪽 회색 박스)
- 사용자의 입력은 텍스트 단독 또는 텍스트 + 멀티모달 데이터 조합이다.
- 예:
- “고양이가 피아노 치는 장면 보여줘” → text + image
- “이 소리는 무엇인가요?” → text + audio
- “이 영상의 설명을 알려줘” → text + video
- 예:
2. Input Encoding 및 Projection (좌측 중앙)
- 이미지, 오디오, 비디오 입력은 각각의 Encoder에서 특성 추출 후,
- Input Projection Layer를 통해 LLM이 이해할 수 있는 언어 기반 표현으로 변환된다.
- Text-only 입력의 경우 projection 없이 바로 LLM 입력으로 사용됨.
3. LLM + LoRA 기반 Instruction Tuning
- LLM은 지시문을 기반으로 텍스트 출력과 함께
- 필요한 경우 멀티모달 생성 지시를 포함한 특별 토큰 (e.g. <IMG₀>, <VID₂>)을 생성한다.
- 이때 LoRA 기법을 사용해 LLM 일부만 경량 학습된다.
- (그림에서 LLM 블록에 붙은 "LoRA 🔥"이 이를 의미함)
4️⃣ LLM Output vs Gold Annotation 비교
- 실제 생성된 텍스트 + signal token 시퀀스와
- 정답 시퀀스(Gold Annotation)를 Cross Entropy Loss로 비교하여 학습.
5️⃣ Signal Token → Output Projection → Diffusion
- LLM이 생성한 signal token 표현은 각 modality별 Output Projection Layer를 거쳐,
- Diffusion Decoder로 전달된다.
- 여기서 실제 멀티모달 콘텐츠(이미지, 오디오, 비디오)를 생성한다.
6️⃣ 생성 결과 평가 (Generation Loss)
- 생성된 이미지/오디오/비디오와
- 정답 multimodal caption (Gold Annotation)을 비교하여 Generation Loss를 계산한다.
요점 정리
단계 내용 입력 텍스트 + 멀티모달 (이미지, 오디오, 비디오) 목표 지시문에 따라 멀티모달 응답을 정확히 생성 LLM 역할 텍스트 생성 + 멀티모달 생성 지시(signal token) 출력 학습 LoRA 기반 LLM tuning + Output projection 정렬 손실 함수 Cross Entropy + Generation Loss 결과 유저 지시에 따라 다양한 모달 생성이 가능한 MM-LLM
이 방식은 단순히 모달리티를 "받고 해석하는 것"을 넘어서, 사용자 지시를 이해하고 능동적으로 텍스트/이미지/오디오/비디오를 생성할 수 있는 AI 시스템을 만드는 데 핵심이 된다.
4. 실험 결과 요약
NExT-GPT는 모달 인식 능력(perception)과 콘텐츠 생성 능력(generation) 양쪽에서 모두 강력한 성능을 보였다. 다양한 벤치마크와 비교 실험을 통해 그 효과가 입증되었으며, 추가적으로 모듈 구성 요소들의 영향 분석도 수행되었다.
1. 멀티모달 인식 성능 (Multimodal Perception)
- 이미지 인식
- Image Captioning, Image QA 등에서 SOTA 수준 성능 달성.
- MMBench, SEED-Bench 등 평가 전용 벤치마크에서도 높은 정답률.
- 비디오 및 오디오 인식
- WebVid-2M (Video), AudioCaps (Audio) 기반 평가에서 우수한 이해 및 문장 생성 성능 보임.
- LLM 기반 직접 생성으로 문맥 표현력이 뛰어남.
2. 멀티모달 생성 성능 (Multimodal Generation)
- 텍스트로부터 이미지·영상·오디오 생성 품질 비교
- Stable Diffusion (이미지), Zeroscope (영상), AudioLDM (오디오) 활용.
- LLM이 modality signal token을 통해 직접 지시하는 방식이라 제어력과 표현력에서 우수함.
- 비교 모델: GILL, Emu, UIO-2XXL, Codi 등
- 대부분의 비교 모델보다 다양한 modality 조합을 지원하며, zero-shot 상황에서도 성능 유지.
3. 정량적 분석 – signal token 수의 영향
- modality별로 필요한 signal token 개수가 다름:
- 이미지: 4개, 오디오: 8개, 영상: 24개 이상 필요.
- 데이터 양과 디퓨전 모델 강도에 따라 성능이 민감하게 변화.
4. 구성 요소별 영향 실험
- Grouping Mechanism 효과
- 단순 Linear Layer → 성능 급감.
- Q-Former 도입 → 일부 개선.
- NExT-GPT의 Grouping Mechanism이 가장 효과적.
- Pipeline vs End-to-End 구조 비교
- 사람이 판단한 instruction-following, 합리성, 생성 품질 평가에서 end-to-end 구조가 월등히 우수.
5. 정성적 분석 (Qualitative Analysis)
- 직관적 예시 제공:
- 영상에서 비정상 행동 감지 후 유사한 이미지와 오디오 생성.
- 사용자의 감정을 감지하고 위로용 영상 자동 생성 (e.g., 강아지 영상).
- 프레젠테이션 준비 시 시각 자료 + 요약 팁 생성.
- Implicit Instruction 이해
- 명확한 지시가 없어도 사용자 감정이나 목적을 파악해 적절한 modality 선택 및 생성 수행.
5. 결론 및 핵심 기여
NExT-GPT는 end-to-end 구조의 범용 any-to-any 멀티모달 LLM으로, 텍스트, 이미지, 오디오, 비디오를 자유롭게 입력과 출력으로 사용할 수 있는 강력한 시스템이다. 기존의 파이프라인 방식이 가진 한계를 극복하고, 다음과 같은 장점을 가진다:
- 다양한 modality를 연결하는 모듈형 구조
- 기존의 고성능 encoder·decoder 재활용으로 학습 비용 최소화
- 전체 파라미터의 1%만 학습하는 lightweight 전략
- 고품질 instruction tuning dataset (MosIT) 구축 및 활용
- 복잡한 cross-modal reasoning과 generation 가능
주요 기여
- 최초의 범용 any-to-any MM-LLM 제안
- 텍스트, 이미지, 오디오, 비디오를 자유롭게 인식하고 생성 가능.
- LLM 기반으로 reasoning 능력을 내장하여 사람과 유사한 질의응답 수행.
- 경량 정렬 학습 기법 도입
- 인코딩 측: LLM-centric multimodal alignment
- 디코딩 측: Instruction-following alignment
- 전체 시스템의 단 1%만 미세 조정하는 고효율 구조
- MosIT: 고품질 modality-switching instruction 튜닝 데이터셋 구축
- 5,000개 이상의 멀티모달 대화 샘플 수동 생성 및 검수
- 다양한 topic과 modality 조합, multi-turn 대화, implicit 명령까지 커버
6. 이 연구의 의의와 우리에게 주는 시사점
연구의 의의
- 범용 any-to-any 멀티모달 LLM의 첫 구현 사례
- → 다양한 입력과 출력을 자유롭게 조합할 수 있는 인간 유사 인공지능의 초석
- 모듈식 구조 + 경량 학습 전략 → 확장성과 효율성 모두 확보
- → LLM은 고정(frozen)된 상태에서 projection 계층만 미세 조정 → 학습 비용 절감
- 기존의 파이프라인 방식의 한계 극복 (비연속, 오류 누적, 추론력 부족)
- → end-to-end 방식의 통합 학습 구조로 의미 있는 개선
우리 프로젝트와의 직접적 연결
- 우리는 “모델에 새로운 modality 추가” 실험을 담당
- → NExT-GPT의 구조는 새 modality를 추가하는 데 매우 적합한 설계
- 새로운 modal을 넣을 때 해야 할 핵심 작업:
- 새로운 modality에 맞는 Encoder 선택 or 구축
- Input projection layer 학습
- Modality signal token 정의 및 학습
- (필요 시) Output projection + diffusion decoder 연결
- 💡 즉, NExT-GPT의 구조는 우리가 실험을 설계하고 적용할 수 있는 직접적인 가이드라인 역할
'논문 정리' 카테고리의 다른 글
GroundingDINO 정리 (4) 2025.07.09